In the last post we have used Aggregator Transformation to remove the duplicate records. In this post we will use the Expression transformation to remove the duplicate JOB_ID from the source Flat file.
Sorter – To sort the source records (To improve Aggregator Performance) Expression – To compare the current and previous value and assign duplicate count Filter – To Filter out the duplicate records
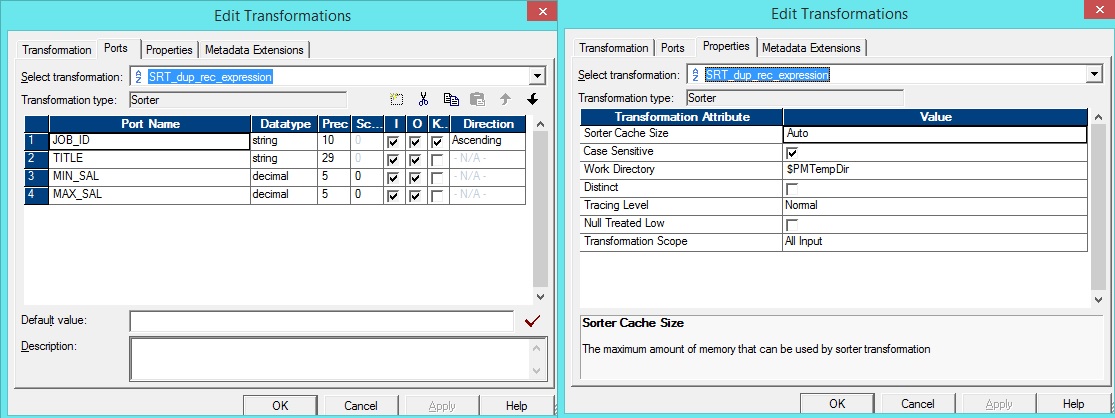
Source Flat File having duplicate JOB_IDComplete Mapping with Sorter, Expression & FilterHave a close look on the transformations and understand how we connected the ports.Sorter Transformation – Here we are sorting the record using key JOB_ID.Expression Transformation – To compare the current JOB_ID with the previous ID and increment a counter if both are matching, For those duplicate records the counter will be 1 or greater.
Here is the variable & output ports used in Expression.
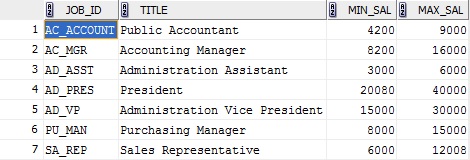
Filter Transformation – Process only if the counter is Zero, it means there is no duplicate Job_ID. Everything else will be skipped.Workflow Log – 4 duplicate records got removed from the source and everything else got loaded in to target.Target Table – See the results now, We have only unique JOB_ID in the target table.